

 Twitter dévoile une partie de son code source, dont son algorithme de recommandation,
Twitter dévoile une partie de son code source, dont son algorithme de recommandation,peu de temps après une fuite dudit code source sur GitHub. Elon Musk fait une analogie à Linux et sollicite l'aide de la communauté
Près d'un an après qu'Elon Musk a lancé pour la première fois l'idée de rendre public l'algorithme de recommandation de Twitter, la société a publié le code source de son algorithme de recommandation sur GitHub. Dans un Twitter Space discutant de cette décision, Musk a déclaré qu'il espérait que les utilisateurs seraient en mesure de trouver des « problèmes » potentiels dans le code et de contribuer à l'améliorer.
Toutefois, le code publié vendredi ne traite que de la façon dont les tweets sont affichés dans le flux « Pour Vous » de Twitter. La société n'a pas publié le code sous-jacent de son algorithme de recherche ni la manière dont le contenu est affiché sur d'autres parties de Twitter, bien que Musk ait déclaré que la société ouvrirait également « à coup sûr » l'algorithme de recherche.
Le timing est également intéressant. Des parties du code source de Twitter ont été divulguées en ligne via GitHub peu de temps avant. Le réseau social a déposé une demande de retrait en vertu de la loi américaine DMCA. La demande, que GitHub a publiée en ligne, indique que les informations divulguées comprenaient « le code source exclusif de la plateforme de médias sociaux et des outils internes de Twitter ». Certains se demandent si ce n'est pas cet évènement qui a un peu forcé la main à Elon Musk.
Comme promis à plusieurs reprises par le PDG de Twitter, Elon Musk, Twitter a ouvert une partie de son code source à l'inspection publique, y compris l'algorithme qu'il utilise pour recommander des tweets dans la chronologie des utilisateurs.
Sur GitHub, Twitter a publié deux référentiels contenant du code pour de nombreuses parties qui font fonctionner le réseau social, y compris le mécanisme utilisé par Twitter pour contrôler les tweets que les utilisateurs voient sur la chronologie Pour Vous.
Dans un billet de blog décrivant le fonctionnement des recommandations de Twitter, la société a expliqué les différentes étapes de l'algorithme, y compris le classement et le filtrage. Ceux qui sont intéressés peuvent trouver un extrait ci-dessous.
Comment choisissons-nous les Tweets ?
La base des recommandations de Twitter est un ensemble de modèles et de fonctionnalités de base qui extraient des informations latentes des tweets, des utilisateurs et des données d'engagement. Ces modèles visent à répondre à des questions importantes sur le réseau Twitter, telles que « Quelle est la probabilité que vous interagissiez avec un autre utilisateur à l'avenir ? » ou, « Quelles sont les communautés sur Twitter et quels sont les Tweets à la mode en leur sein ? » Répondre à ces questions avec précision permet à Twitter de fournir des recommandations plus pertinentes.
Le pipeline de recommandations est composé de trois étapes principales qui consomment ces fonctionnalités :
Le service responsable de la construction et du service de la chronologie Pour Vous s'appelle Home Mixer. Home Mixer est construit sur Product Mixer, notre framework Scala personnalisé qui facilite la création de flux de contenu. Ce service agit comme l'épine dorsale du logiciel qui relie différentes sources de candidats, fonctions de notation, heuristiques et filtres.
Le diagramme ci-dessous illustre les principaux composants utilisés pour construire une chronologie*:
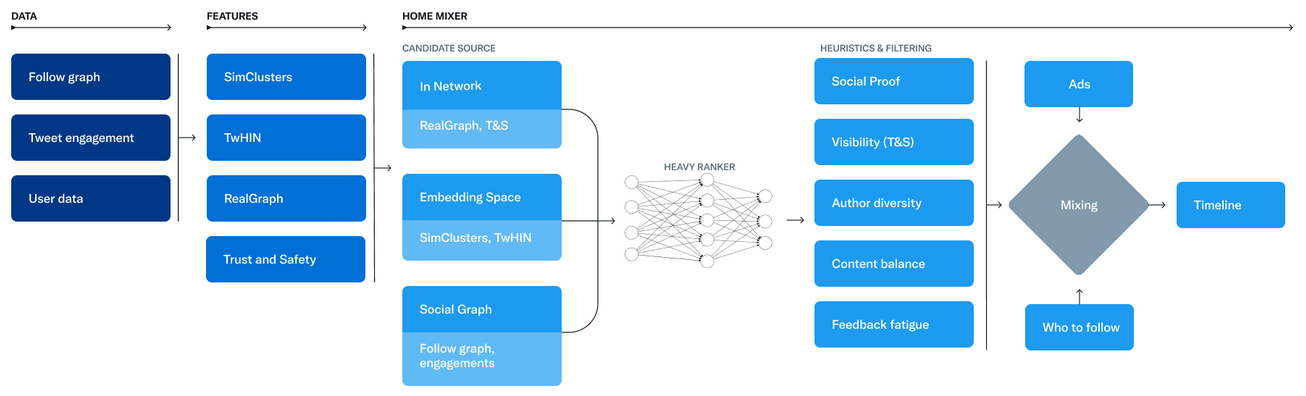
[ndlr. Des détails sont donnés à ce niveau concernant entre autres les sources de candidats]
Classement
L'objectif de la chronologie Pour Vous est de vous proposer des Tweets pertinents. À ce stade du pipeline, nous avons environ 1500 candidats qui pourraient être pertinents. La notation prédit directement la pertinence de chaque Tweet candidat et constitue le principal signal de classement des Tweets sur votre journal. À ce stade, tous les candidats sont traités de la même manière, quelle que soit la source du candidat dont ils proviennent.
Le classement est réalisé avec un réseau neuronal d'environ 48 millions de paramètres qui est continuellement formé sur les interactions Tweet pour optimiser l'engagement positif (par exemple, J'aime, Retweets et Réponses). Ce mécanisme de classement prend en compte des milliers de fonctionnalités et produit dix étiquettes pour donner à chaque Tweet un score, où chaque étiquette représente la probabilité d'un engagement. Nous classons les Tweets à partir de ces scores.
Heuristiques, filtres et fonctionnalités du produit
Après l'étape de classement, nous appliquons des heuristiques et des filtres pour implémenter diverses fonctionnalités du produit. Ces fonctionnalités marchent ensemble pour créer un flux équilibré et diversifié. Voici quelques exemples :
La base des recommandations de Twitter est un ensemble de modèles et de fonctionnalités de base qui extraient des informations latentes des tweets, des utilisateurs et des données d'engagement. Ces modèles visent à répondre à des questions importantes sur le réseau Twitter, telles que « Quelle est la probabilité que vous interagissiez avec un autre utilisateur à l'avenir ? » ou, « Quelles sont les communautés sur Twitter et quels sont les Tweets à la mode en leur sein ? » Répondre à ces questions avec précision permet à Twitter de fournir des recommandations plus pertinentes.
Le pipeline de recommandations est composé de trois étapes principales qui consomment ces fonctionnalités :
- récupérer les meilleurs Tweets à partir de différentes sources de recommandation dans un processus appelé recherche de candidats ;
- classer chaque Tweet à l'aide d'un modèle d'apprentissage automatique ;
- appliquer des heuristiques et des filtres, tels que le filtrage des Tweets des utilisateurs que vous avez bloqués, du contenu NSFW et des Tweets que vous avez déjà vus.
Le service responsable de la construction et du service de la chronologie Pour Vous s'appelle Home Mixer. Home Mixer est construit sur Product Mixer, notre framework Scala personnalisé qui facilite la création de flux de contenu. Ce service agit comme l'épine dorsale du logiciel qui relie différentes sources de candidats, fonctions de notation, heuristiques et filtres.
Le diagramme ci-dessous illustre les principaux composants utilisés pour construire une chronologie*:
[ndlr. Des détails sont donnés à ce niveau concernant entre autres les sources de candidats]
Classement
L'objectif de la chronologie Pour Vous est de vous proposer des Tweets pertinents. À ce stade du pipeline, nous avons environ 1500 candidats qui pourraient être pertinents. La notation prédit directement la pertinence de chaque Tweet candidat et constitue le principal signal de classement des Tweets sur votre journal. À ce stade, tous les candidats sont traités de la même manière, quelle que soit la source du candidat dont ils proviennent.
Le classement est réalisé avec un réseau neuronal d'environ 48 millions de paramètres qui est continuellement formé sur les interactions Tweet pour optimiser l'engagement positif (par exemple, J'aime, Retweets et Réponses). Ce mécanisme de classement prend en compte des milliers de fonctionnalités et produit dix étiquettes pour donner à chaque Tweet un score, où chaque étiquette représente la probabilité d'un engagement. Nous classons les Tweets à partir de ces scores.
Heuristiques, filtres et fonctionnalités du produit
Après l'étape de classement, nous appliquons des heuristiques et des filtres pour implémenter diverses fonctionnalités du produit. Ces fonctionnalités marchent ensemble pour créer un flux équilibré et diversifié. Voici quelques exemples :
- filtrage de la visibilité : filtrez les Tweets en fonction de leur contenu et de vos préférences. Par exemple, supprimez les Tweets des comptes que vous bloquez ou désactivez ;
- diversité des auteurs : évitez trop de Tweets consécutifs d'un même auteur ;
- équilibre du contenu : Assurez-vous que nous diffusons un juste équilibre entre les Tweets In-Network et Out-of-Network ;
- fatigue basée sur les commentaires : réduisez le score de certains Tweets si le spectateur a fourni des commentaires négatifs autour de ceux-ci ;
- preuve sociale : Exclure les Tweets Out-of-Network sans connexion de second degré au Tweet comme garantie de qualité. En d'autres termes, assurez-vous qu'une personne que vous suivez interagit avec le Tweet ou suit l'auteur du Tweet ;
- conversations : fournissez plus de contexte à une réponse en l'associant au Tweet d'origine ;
- tweets modifiés : déterminez si les Tweets actuellement sur un appareil sont obsolètes et envoyez des instructions pour les remplacer par les versions modifiées.
Lors d'une session Twitter Spaces, Musk a précisé : « Notre version initiale du soi-disant algorithme va être assez embarrassante, et les gens vont trouver beaucoup d'erreurs, mais nous allons les corriger très rapidement ». Et d'ajouter « même si vous n'êtes pas d'accord avec quelque chose, au moins vous saurez pourquoi c'est là, et que vous n'êtes pas secrètement manipulé... L'analogue, ici, auquel nous aspirons est le grand exemple de Linux en tant que système d'exploitation open source On peut, en théorie, découvrir de nombreux exploits pour Linux. En réalité, ce qui se passe, c'est que la communauté identifie et corrige ces exploits ».
Sur ce deuxième point du billet de blog sur la prévention des risques, les versions open source n'incluent pas le code qui alimente les recommandations publicitaires de Twitter ou les données utilisées pour former l'algorithme de recommandation de Twitter. De plus, elles incluent peu d'instructions sur la façon d'inspecter ou d'utiliser réellement le code, ce qui renforce l'idée que les versions sont strictement axées sur les développeurs.
« [Nous avons exclu] tout code qui compromettrait la sécurité et la confidentialité des utilisateurs ou la capacité de protéger notre plateforme contre les acteurs malveillants, y compris saper nos efforts pour lutter contre l'exploitation et la manipulation sexuelles des enfants », a écrit Twitter. Un message qui pourrait paraître un peu surprenant dans la mesure où il vient quelques semaines seulement après que Twitter a licencié une grande partie de son personnel d'IA éthique ainsi que son équipe de confiance et sécurité, qui était responsable de la modération du contenu parmi d'autres tâches liées à la sécurité des utilisateurs. Mais la société insiste néanmoins sur le fait qu'elle « [a pris] des mesures pour garantir que la sécurité et la confidentialité des utilisateurs seraient protégées » avec la publication du code.
Twitter indique qu'il travaille sur des outils pour gérer les suggestions de code de la communauté et synchroniser les modifications apportées à son référentiel interne. Vraisemblablement, ceux-ci seront mis à disposition à une date ultérieure.
« Nous allons chercher des suggestions, non seulement sur les bogues, mais aussi sur la façon dont l'algorithme devrait fonctionner », a déclaré Musk lors de la session Spaces. « Ce sera un processus évolutif. Je ne m'attendrais pas à ce que ce soit un mouvement ascendant ininterrompu mais nous sommes très ouverts à ce qui améliorerait l'expérience utilisateur ».
Des utilisateurs ont déjà trouvé des détails intéressants dans le code lui-même
Dans son billet de blog décrivant le fonctionnement des recommandations de Twitter, la société a expliqué les différentes étapes de l'algorithme, y compris le classement et le filtrage. Mais les utilisateurs de Twitter ont déjà trouvé des détails intéressants dans le code lui-même. Par exemple, Jane Manchun Wong a noté que « l'algorithme de Twitter indique spécifiquement si l'auteur du Tweet est Elon Musk ». Cela peut offrir une autre explication de la raison pour laquelle les tweets de Musk apparaissent si souvent. Wong a également noté que l'algorithme comporte des étiquettes indiquant si l'auteur du tweet est un « utilisateur expérimenté » ainsi que s'il est républicain ou démocrate.
[TWITTER]<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Twitters algorithm specifically labels whether the Tweet author is Elon Musk<br><br>author_is_elon<br><br>besides the Democrat, Republican and Power User labels<a href="https://t.co/fhpBjdfifX">https://t.co/fhpBjdfifX</a> <a href="https://t.co/orCPvfMTb9">pic.twitter.com/orCPvfMTb9</a></p>— Jane Manchun Wong (@wongmjane) <a href="https://twitter.com/wongmjane/status/1641884551189512192?ref_src=twsrc%5Etfw">March 31, 2023</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> [/TWITTER]
Interrogé sur cet aspect de l'algorithme dans Twitter Space, Musk a déclaré: « Je suis d'accord que cela ne devrait pas être là cela ne devrait certainement pas diviser les gens en républicains et démocrates, cela n'a aucun sens ». Un ingénieur de Twitter a ensuite précisé que les catégories n'étaient destinées qu'à « des fins de suivi des statistiques et que cela n'avait rien à voir avec l'algorithme ». Il a déclaré que les étiquettes visaient à « s'assurer que nous ne privilégions pas un groupe par rapport à un autre », bien qu'il n'ait pas expliqué pourquoi Musk avait sa propre catégorie.
« Mais n'est-ce pas bizarre que vous ayez quatre catégories et que l'une d'elles soit Elon ? », a demandé un internaute. « Je pense que c'est bizarre », a reconnu Musk. « C'était la première fois que j'apprenais ça ».
Rien n'a filtré sur les fameux 35 utilisateurs VIP
Une chose qui ne semble pas avoir été rendue publique est la liste des VIP boostée par Twitter. Selon un rapport de Platformer, Twitter a toujours montré une préférence claire pour certains de ses utilisateurs les plus en vue. Une liste secrète de 35 utilisateurs expérimentés de Twitter dont les comptes sont marqués VIP bénéficient actuellement d'une visibilité accrue dans les flux, les ingénieurs allant même jusqu'à modifier le code pour s'assurer qu'ils apparaissent dans l'onglet « Pour vous ».
Les ingénieurs de Twitter ont veillé à ce que les tweets de ces utilisateurs VIP soient automatiquement plus visibles que les autres, a déclaré Platformer. Les tweets des utilisateurs VIP contournent également un algorithme Twitter qui empêche l'affichage d'un trop grand nombre de messages d'un utilisateur particulier, selon Platformer.
Zoë Schiffer, rédactrice en chef de Platformer, a cité des documents internes de Twitter qui répertorient 35 utilisateurs VIP dont les publications sont surveillées et promues pour une plus grande visibilité. Schiffer a publié 14 des 35 noms de la liste, dont Lebron James, la star de la NBA ; M. Beast, un éminent YouTuber ; la représentante Alexandria Ocasio-Cortez, la politicienne américaine ; Ben Shapiro, le commentateur conservateur ; et le propre PDG de Twitter, Elon Musk. La liste comprenait également le commentateur pro-Trump, catturd2, avec qui Elon Musk a eu de nombreuses conversations sur Twitter.
Les 14 noms répertoriés semblaient également couvrir l'éventail politique. Le président Joe Biden figurait sur la liste des 14 utilisateurs de Platformer, mais pas l'ancien président Donald Trump (bien que ce dernier publie désormais exclusivement sur Truth Social, malgré le rétablissement de son compte Twitter en novembre).
Toutes les personnes sur la liste ne sont pas des fans de Musk. Le PDG de Twitter a une longue histoire de querelle publique avec Ocasio-Cortez. En décembre, Musk a eu une dispute sur Twitter avec Ocasio-Cortez, au cours de laquelle elle lui a dit de « mettre fin au proto-fascisme » et de poser son téléphone.
Cette liste contraste fortement avec la quête d'Elon Musk de « traiter tout le monde de la même manière ».
Certaines parties du code de Twitter étaient en fait déjà rendues open source, mais pas comme Musk l'avait prévu. Il y a quelques jours, il a été annoncé que des parties du code source de Twitter avaient été téléchargées (upload) sur GitHub selon des documents judiciaires, dans lesquels Twitter exigeait que les parties de code incriminées soient supprimées du référentiel en ligne. Twitter a également déposé un avis de retrait DMCA auprès de GitHub, qui a été conforme à la demande de suppression du code.
On ne sait pas quelle quantité de code a été téléchargée ni combien de temps il a été laissé en ligne. Les morceaux de code source ont été téléchargés par un utilisateur qui se fait appeler "FreeSpeechEnthusiast" (peut-être un clin d'il aux tentatives faillibles d'Elon Musk d'être un « absolutiste de la liberté d'expression »).
Quoiqu'il en soit, un tribunal de première instance du district du nord de la Californie a répondu favorablement à la demande d'Elon Musk d'obliger GitHub à lui révéler l'identité de l'auteur de la fuite de certaines parties du code source de Twitter. Il a obtenu une assignation à comparaître obligeant GitHub à produire toutes les informations d'identification associées au compte "FreeSpeechEnthusiast" d'ici le 3 avril.
 Code source de l'algorithme (1, 2)
Code source de l'algorithme (1, 2)Source : Twitter
Et vous ?
Que pensez-vous de la décision de Twitter de publier une partie de son code source en open source ? Que pensez-vous du timing avec les fuites sur GitHub ? Ont-elles, selon vous, forcé la main à Elon Musk ? Dans quelle mesure ? « L'analogue, ici, auquel nous aspirons est le grand exemple de Linux en tant que système d'exploitation open source
On peut, en théorie, découvrir de nombreux exploits pour Linux. En réalité, ce qui se passe, c'est que la communauté identifie et corrige ces exploits ». Que pensez-vous de cette déclaration d'Elon Musk ? Tentative de faire travailler gratuitement des bénévoles après avoir licencié son personnel ? Que pensez-vous des catégories politiques (démocrates, républicains) dans l'algorithme de Twitter et de l'explication donnée par l'ingénieur Twitter pour expliquer leur raison d'être ? Qu'est-ce qui pourrait, selon vous, expliquer qu'Elon Musk dispose lui aussi d'une catégorie dans l'algorithme ? Le fait qu'Elon Musk affirme qu'il n'en savait rien est-il crédible ? Il faut rappeler qu'à un moment donné, Elon Musk a demandé à ce que chaque ingénieur lui présente son code.
Vous avez lu gratuitement 2 221 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.


